Weeknotes: 31st July 2023
Things I did last week
Tropical Moist Forest Evaluation Methodology Implementation
This last week I managed to get the pixel matching algorithm from TMFEMI complete, enabling Patrick to plug it into his work and in theory letting us generate some project evaluations.
Unfortunately, although things had been running okay for me in development, taking 75 minutes to do 100 matching iterations as required by the methodology document, when Patrick automated it into the pipeline, we hit two problems:
- I’d done my work on one of our compute servers, and was able to run all 100 iterations concurrently due to that machine having more than 100 cores and enough memory to host all 100 instances. The machine Patrick is using as his CI server has much fewer cores and memory, and so we could only run 25 threads at once.
- That machine is also just was slower per thread - the compute server took 75 minutes per thread, where as the CI server took closer to three hours per thread.
All added together this meant the pixel matching for additionally went from 75 minutes to ten hours. Things then got worse when we looked at leakage. The leakage zone around a project is inherently bigger, and for out test forest project this meant the number of pixels to be matched jumped by roughly a factor of two, which then also doubles the samples to be searched (as that’s proportional to the match pixel size), meaning we had 4 times as much work to do, and projection was this would take 3 days!
So, despite my reluctance to optimise a thing when we don’t even know if the pipeline is generating correct results yet, I did some profiling as suggested by Patrick and reading up on pandas best practices, and after a bunch of work got the run on the compute server down from 75 minutes to just under ten minutes, and for my profiling runs down from 9500 seconds to 750 seconds for my sample thread (profiling code makes it slower, which is why 75 minutes jumped to near three hours).
From my subsequent PR:
I did some profiling and reading up on pandas performance, and got the speed for this stage down to about 10% of the original.
The main issue, flagged by the profiler, is that accessing the columns on a row is expensive, with most of the time being spent in Python's get_attr method. Moving to having columns already filtered and then just selecting the row and calling tolist() on the row gave us most of the performance win.
The secondary issue is that panda's apply method internally is doing the same as iterrows, and threads on the internet indicated that itertuples() is generally faster, and that gave us another boost in performance. Apparently taking the data out of pandas entirely and using numpy directly would be another option, but for now I felt getting it down to 10% was good enough to be getting on with, given that the code is still relatively readable.
I have to confess, after my experience trying to reimplement bits of numpy in Swift and discovering that numpy is pretty damn efficient at what it does, I was skeptical that pandas would be the root cause of what was slowing us down, but it turns out to be a combination of the python run time and pandas that were our enemy here. I’ll turn this into a small blog post later this week before I forget it all.
Anyway, this is now back to Patrick to see how it fairs on the CI server.
That said, even with this performance increase, when we need to evaluate dozens of projects at a time, that CI server is clearly too slow, so as discussed at the TMFEMI planning meeting on Friday, we plan to do some shuffling of compute resources across 4C as a result:
- We will move the 4C pipeline runner from the CI server to one of our compute servers. That machine will be phased out as a generally accessible compute node and move to being a 4C pipeline node. This will be more important as we move to supporting other things in the pipeline in the near future (e.g., the biodiversity pipeline as part of generating data for IUCN).
- We will move the GPU out of the chosen server to another machine, as our pipeline doesn't require it currently. People who use that machine for CPU do so because they need all the cores/memory, and those using the GPU tend not to use much at all, so it makes sense to split those out.
Server upgrades
This week I finally managed to schedule software updates for the 4C machine pool, but they did not go as I’d hoped. The main objective was to get both machines onto a newer kernel as the 5.x series they were on does not have support for AMD EPYC CPUs, and the 6.1 kernel release had improvements for such machines as a headline feature.
Firstly, I tackled Kinabalu, as it’s less used than Sherwood. Unfortunately because Kinabalu has a NVIDIA GPU, my attempts to update the machine failed. NVIDIA don’t support CUDA on Ubuntu 23.04, which had been my initial intention as a lazy way to omve to a newer kernel rather than patching 22.04 LTS. So instead I looked at just upgrading the kernel to 6.4 (the latest stable release), and CUDA wouldn’t work with this either. So in the end Kinabalu did not receive updates, as to do so would stop people using the GPU there (which they do). But this is not a good state to be in, as we have a very expensive computer that is using a kernel that can’t fully take advantage of it. But since this we have agreed we should move the GPU to another machine, so I’ll work with Anil and Sadiq to make that happen, and then we can update Kinabalu.
Given I couldn’t update the Ubuntu on Kinabalu, I also did not update the OS on Sherwood, as it makes my like easier if all the machines in the 4C pool run the same OS version. I did however update Sherwood to kernel 6.4.6. So far I’ve had no reports of issues.
Mollweide projection of H3 tiles
Alison Eyres has been working with an external collaborator, generating hex tile data for them from the LIFE biodiversity pipeline code. However, said collaborator needed the results on Mollweide projection, rather than the usual WGS 84 maps we tend to use. Yirgacheffe doesn’t yet support projections other than WGS84, and so I had a look at whether I could help write some code to make the maps they needed.
Given the time pressure to get it done by the end of the week I didn’t manage to add the code into Yirgacheffe, but I did manage to get something working, even if my first version might have had a sign wrong somewhere :)
With that fixed, I was then able to do some processing of the data, and although I failed to visualise that, Alison was able to confirm it worked:
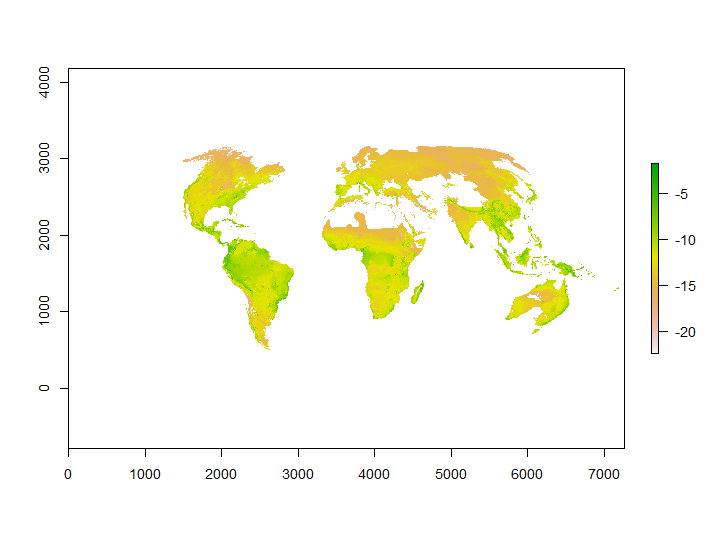
Mollweide is interesting because it breaks a number of assumptions I had about geospatial data when I first wrote Yirgacheffe, so I’ll need to have a think about how to support it properly in future releases. In particular, I built in the assumption that for a view on a map I just need one coordinate and then width and height, but windows on Mollweide end up being trapezoidal rather than rectangular as I'd naively assumed.
Local GEDI Source of Truth
Patrick and I had a catch up with fellow group member Amelia Holcomb at the end of the week, and we discussed a bunch of things where our interest overlapped. One that I want to action reasonably soon is moving people from using Amelia’s GEDI database, which is populated with v1 data, to the one that Patrick and I have started populating with v2 data. However, to prevent accident, I want to have requests for it to be populated with data go via a small REST API, rather than giving people write access to the database. They will still be able to read using Amelia’s GEDI code, but to write I’ll turn Amelia’s fetch and insert code into a small web service that runs on our postgis server.
This coming week
- We want to get data for our standard test project out of the TMFEMI data this week over to Tom Swinfield, so I’ll be dealing with any issues that crop up there as a priority
- I now have access to the TIST database we're meant to be providing access to for local researchers to use. I plan to make a local mirror of that so they can work on it without risk of accidentally impacting the original database in any way.
- Look into the GEDI fetch/load service
- Prepare for a student internship starting next week
Tags: weeknotes, tmfemi, yirgacheffe